
How can I make a crawler that can crawl through Yahoo, Bing, and other search engines to find the top 10 websites that appear as you search for a certain keyword.
Depends on what you wanna do…
but IMO… you could use Simple HTML DOM:
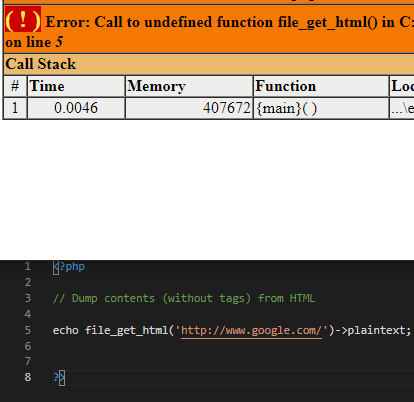
should I put the code inside php tags? this is the error I am getting
(I just tried the code on the documentation)
??
Does even look like you included the class/script?
include('simple_html_dom.php');
I have vast experience in scrapers. What type of data are you attempting to scrape? Just curious…
it is just an assignment for searching a certain keyword and then returning the top 10 websites that is related with the keyword
can I have a sample code?
Well, something loosely like this should work.
You would need to count to 10 and and the input from a form page. This example looks for “apples”…
‘’’
$html = file_get_contents(’ https: //www.google.com/search?q=apples’);
// Create a new DOM document ( Uses standard PHP DOM commands )
$dom = new DOMDocument;
// Load the HTML. The @ is used to suppress any parsing errors that will be thrown if the $html string isn’t valid XHTML.
@$dom->loadHTML($html);
// Get all links on the page
$links = $dom->getElementsByTagName(‘a’);
// Loop thru extracted links and display their URLs
foreach ($links as $link){
echo $link->nodeValue;
echo $link->getAttribute(‘href’), ‘< br>’;
}
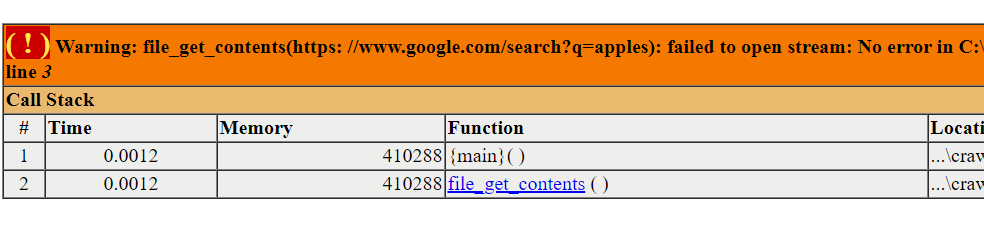
Is this how should I write this?
<?php
$html = file_get_contents('https: //www.google.com/search?q=apples');
// Create a new DOM document ( Uses standard PHP DOM commands )
$dom = new DOMDocument;
// Load the HTML. The @ is used to suppress any parsing errors that will be thrown if the $html string isn’t valid XHTML.
@$dom->loadHTML($html);
// Get all links on the page
$links = $dom->getElementsByTagName('a');
// Loop thru extracted links and display their URLs
foreach ($links as $link){
echo $link->nodeValue;
echo $link->getAttribute('href'), '< br>';
}
?>
Did you read my comment?
Sorry, there was an extra space after HTTPS: …
uhm… I don’t quite understand the sentence actually.

this is what I got…
should I write . instead of , before the
?
<?php
$html = file_get_contents('https://www.google.com/search?q=apples');
// Create a new DOM document ( Uses standard PHP DOM commands )
$dom = new DOMDocument;
// Load the HTML. The @ is used to suppress any parsing errors that will be thrown if the $html string isn’t valid XHTML.
@$dom->loadHTML($html);
// Get all links on the page
$links = $dom->getElementsByTagName('a');
// Loop thru extracted links and display their URLs
foreach ($links as $link){
echo $link->nodeValue;
echo $link->getAttribute('href')."< br>";
}
?><?php
$html = file_get_contents('https://www.google.com/search?q=apples');
// Create a new DOM document ( Uses standard PHP DOM commands )
$dom = new DOMDocument;
// Load the HTML. The @ is used to suppress any parsing errors that will be thrown if the $html string isn’t valid XHTML.
@$dom->loadHTML($html);
// Get all links on the page
$links = $dom->getElementsByTagName('a');
// Loop thru extracted links and display their URLs
foreach ($links as $link){
echo $link->getAttribute('href'), '<br>';
}
?>
This small routine gets all < A > tags from Google. You picked an odd thing to try to scrape. But, let’s give you the PHP-Scraping-Class-101 on this. Start at the beginning… apples - Google Search
RIGHT-CLICK on it and open in a new window. As you see on this page it is FULL of links, that is why your code shows so many like and most make no sense at all. Now, on that new page, RIGHT-CLICK in a blank area and select VIEW-SOURCE. This will open a new tab with the source of the page so you can view the live data on it. If you remove the display text, the first echo line, as I have in this version, it will just show the link’s HREF info. Might be easier for you to handle just that. But, it will contain all of the links that Google uses for itself and there are a lot of them.
Now, look down the Google page’s source in the new tab and locate the first true link you want to scrape. You should find in inside a class=“g” div. So, you could try capturing the links that are inside that class. In other words, you have to learn every page you scrape. You can just take ALL links on the page and crawl along those. It might work, but, you would be getting a lot of useless Google pages along with your data pages.
Remember that Google IS a search engine! It crawls sites for you. So, most of it’s links are, of course, to itself. That is why so many of the links you find are pointers to other Google pages. You could add code to not show these. All of this is extremely complicated. Google has so many links and most are not the main 10 items.
To remove some or all of the garbage, you can just take HREF’s that have a valid site in them, meaning starting with HTTP or HTTPS. Those mean external links. Also, you would have to strip out Google’s secret codes. To explain, when Google gives you a link and you press on it, it saves the click in that site’s click-counter. As sites are click on more and more, they move up in the list. So, as you see in your output, hopefully the new version with out the first echo, you will see a lot of odd chars new the end of each link. You will see &ved=some-chars at the end of lines. This is part of Google’s special codes. To extra real codes, you would need to remove ones not using HTTP or HTTPS and remove the Google special codes. Then, you would have the real HREF’s.
Hope this helps you understand how complicated your little routine is. Good luck with solving the rest of it…
To scrape a page, you would need to the entire layout of the page you want to scrape. Since you mentioned “crawling” you probably only want the list of sites down lower on the page, but, a true crawler would keep all links.