I do not understand why your files would disappear. But, it might be that you were loading files that had strange code in them that was causing other issues.
As you see by how small amount of code we now have working, you can do a lot if you just think out the logic of it ahead of time. We only use about a dozen lines of code to do this entire process. I have code that scrapes things off of sites like NFL scores and NFL schedules for my football pool. I have pulled weather reports out for others who needed just a certain area. Scraping is hard sometimes, but, for something like this use, it is easy enough… Let us know of your results of your testing… We can help if it does not!
It’s because the Internet is full of crap coded pages and way too much Javascript!
In all my years working with computers, I have never seen a case where you save a file to your hdd, it has a file size, and then later when you open it the file disappears, or the page opens but when you quit out of your browser the .html file disappears.
At any rate, I now have a decent solution to strip out all the Javascript that causes issues when I try to read saved web pages.
I added an “Article name” field to this page, so that when your script runs, the filename is already named to the article name which saves me a few key strokes.
I’m sure there is more that I can do to pretty things up, but for now I think this solution will do.
Now I have about 200 web pages I have to resave…
But THANK YOU for all of your help, and saving me lost of wasted time!! (I was supposed to spend today getting my head back into a coding project from a few years ago, but I needed to get this fixed first because every day I save 5-10 articles and I am soooo backed up right now!!
If you are willing, I definitely could use some more help as I get back into web development.
Never thought I’d see the day where I would even forget HTML coding, but my mind is getting old and brittle!!!
Hopefully I can get back to where I was 3-4 years ago, when I think iw as pretty good at things.
You know, I was thinking out files disappearing… It could be because it was saved as a temporary file.
Those are erased after use. But, I would have to see the code you used for it. But, kind of not important now, I guess…
No problem! Glad to help you! And, there are several others on this site that are aces, a few much better than me. So, when you get your next issue, create a new post and one of us will help you. I am here a lot as I just love helping everyone with their programming puzzles…
[quote=“ErnieAlex, post:23, topic:27724, full:true”]
You know, I was thinking out files disappearing… It could be because it was saved as a temporary file. Those are erased after use. But, I would have to see the code you used for it. But, kind of not important now, I guess…[/quote]
No…
I went into Firefox and surfed to a web page, decided to save it, choose File > Save Page As, gave it a name, and saved it to my computer. Then I went to Finder, and the file was there with a file size. There was a my-article-name.html file and a my-article-name_files folder. I would double-click on the .html file and either it would instantly disappear, or the page would open okay, but once I quit out of Firefox the .html would diappear before my eyes.
Either way, I have a better solution now as the files don’t seem to be disappearing, PLUS I am now stipping out Javascript that was breaking a lot of these saved web pages.
You know, I am listening to so good rock-n-roll now late at night, working away on my code, and forgot how much I missed doing this stuff on late Saturday nights!
It will take me some time to get my head back into LAMP, but the good thing is that I have a kick-ass code base I wrote several years ago, plus I document the s*** out of my code, so that means I have a super-duper guide to getting my head back into LAMP and my website!!
At the same time, my brain is getting old and brittle, and it would be nice to have some coding buddies online who are happy to help. (Sadly, a lot of people on these online coding forums can get rather nasty if you ask for help, but clearly you are of a different mold, and that is good to know!)
If this is only for reading later I strongly suggest you just use one of the tools available for it. They do a much better job at cleaning up the source for later reading, and there are apps and browser extensions for them so you can just click one button to save pages for later.
Raindrop is a very nice service for this
Or if you want to host one yourself I’d suggest giving wallabag a go
Thanks for the suggestion, but here is the issue… I am trying to get accurate local copies so I can use them for future research. Not saying you, but people who think you simply bookmark what you like and it will be there in the future are naive.
The Internet has become all about $$$, and companies are not motivated to leave knowledge out there without paying a price.
I see information come and go on a daily basis, so I do what I can to save the original so it is there when I need it in a week, month or years later.
Until recently, a simple File > Save Page As worked, but for some sites like the New York Times, forget about it!!
Using a combination of different browsers, different approaches, saving as HTML, web archives, PDF and screenshots, I thik I have a good enough approach for my nees, but it certianly is much harder than in the past.
And that is too bad, because I also try to save copies of things for “inspiration” - the new York Times for some gorgeous news articles online, but unfortunately they are a real bit to store locally without an enormous amount of work!
If you are looking for a challenge, I would love to see if you can find a practical way to save an article like this without losing any of the images or web design…
In order to truly benefit from that article, you need to see all of the images and graphics and at least know that there are videos as well.
I used Firefox’s built-in screen-capture and it appeared to capture a WSYIWYG as far as layout, but then you have the issue of the text being unselectable.
That is my end goal for anything I try and capture - I want the flexability and readability of a PDF with the pixel-perfect captring of the webd esign like a photograph.
Definitely a tall order on the modern Internet, but then again, maybe an expert screen-scraper like you knows of some tricks to accomplish this?
Wallabag and the other “read later” apps I’ve tried do save a local copy. If you run Wallabag locally (I have an unraid server I run lots of dockerized apps on) you get a local database of all the content which you can back up.
Wallabag does NOT give you the entire source though by default. So it might not fit your use case. But I’d expect some of the “read later” apps to.
Is that true for popular apps or whatever like Pocket?
I just assumed that all they did was bookmark what you wanted to read on a server, but that if someone like the NYT ever yanked an article then you would have a dead link.
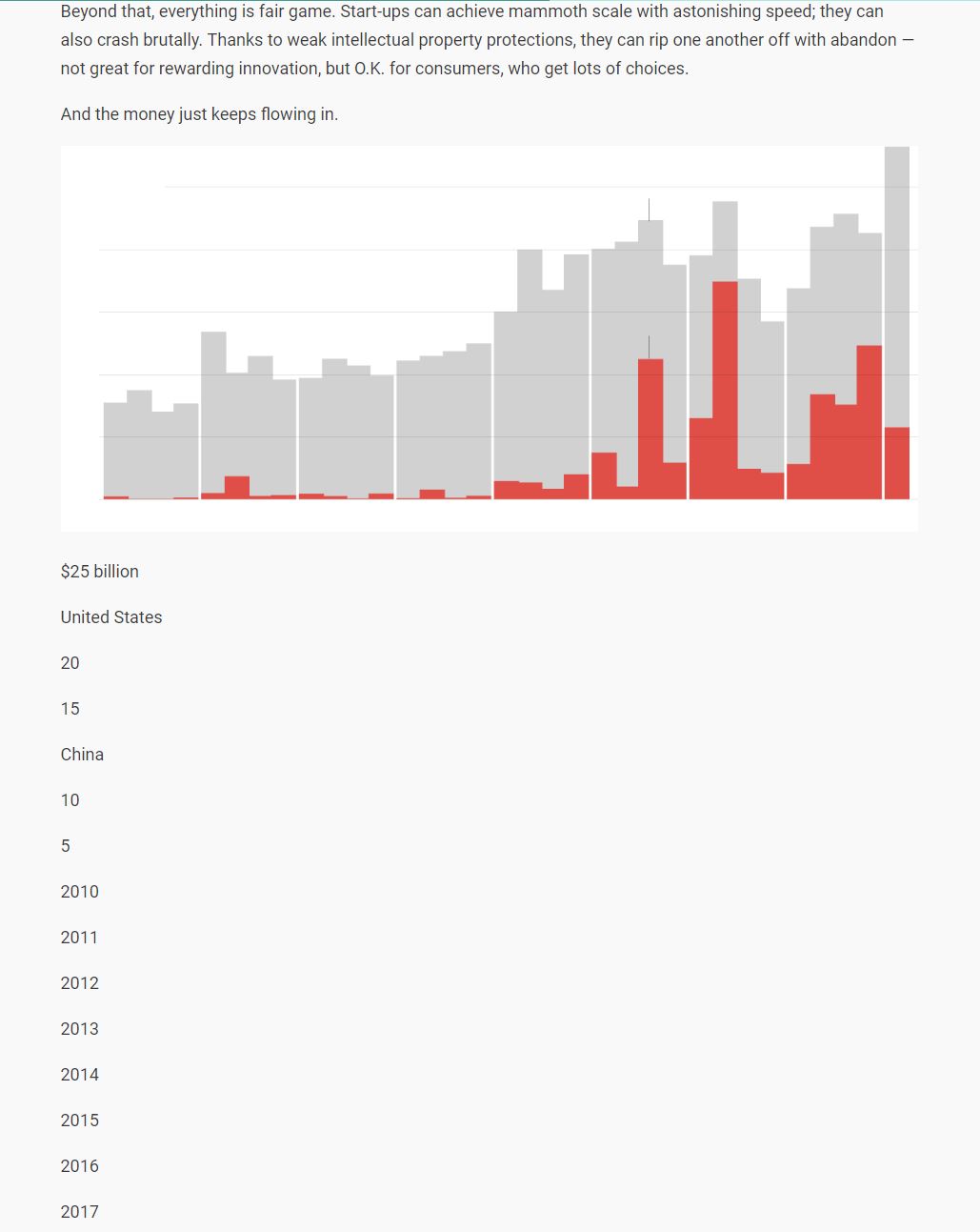
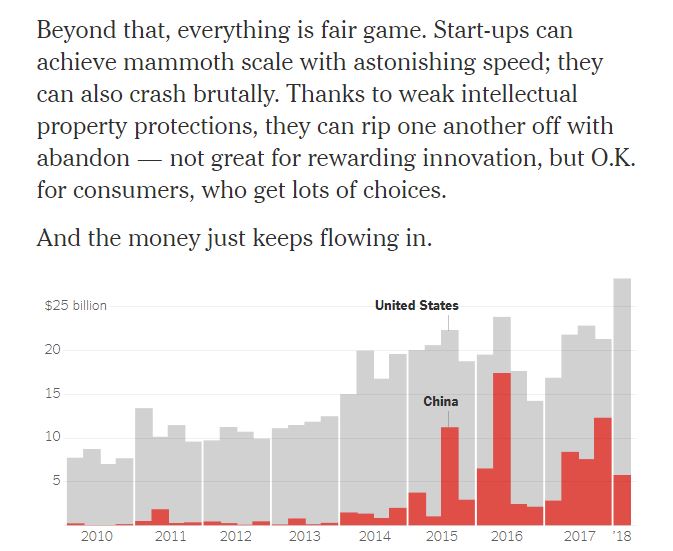
Would be interested to see what you experience of a complex web page like what I referenced above and here again: NYT: How China Walled Off the Internet
So how do you quantify what you do and don’t get?
It’s not that hard for me to find browser plug ins that strip out adds and just give you readable text. But as mentioned before, often times what I want to save includes lots of photos and infographics that further explain what you are reading about. Without that supporting material, the article falls flat.
Think about famous magazines like Time and Life and how “a picture is worth a thousand words”. (It was one thing to read about Vietnam, and quit another to watch a man shot in the head at point blank range in a photograph, right?)
The script you shared with me has been a real life-saver when it comes to me reading (and saving) the nightly news!!
Most pages I have used your script on save well enough to read again later, except some of the more complicated New York Times articles.
However, tonight I went to save a seemingly simple webpage, and to my surprise, when I opened up the saved .html file to verify it was okay - I always do this - it ended up saving your scraping webpage and not the webpage I was trying to save?!
At first I thought it might be an issue with me running NoScript and uMatrix, but I accepted everything, and when I opne the saved file I just see a webpage with the HTML form I used to enter the webpage URL and article title.
Well, there is a lot of clutter on that page. When I scrape pages, I take out the <script tags.
But, I also take out the ads. They are hard to do sometimes. Google-Ads are quite easy as they are clearly marked. Others are tricky to remove.
The problem with removing things is that sometimes the page has script code such as Javascript which loads other parts of the page. So, removing the scripts can make the page mess up sometimes.
So, more on “scraping”… Usually, scraping pages is a very unique process. It is linked individual pages. One pages scraper process does not work on other pages. The routine I helped you with removes the scripts, but, does little else. I have written full site scrapers and have one I am currently working on. It will take a page and save it intact. It will save one entire page or also grab all of the pages that are linked to in the current page. I have used it to take a lot of sites and play with their data. In some cases this is not legal though. So, it is hard for me to promote this type of code. Looking thru my 80TB NAS drive, I found tons of older programs that will grab sites and save them locally. ( I keep tons of old experiments in case I want to revisit them or continue moving them forward! ) I can create a page saver for you that would save a page exactly as it exists. This would take some time. ( I did not see your challenge above as I got really busy the past few days. ) This type of project would not bee too long to do for you.
Another issue with scrapers is that the page you are saving is NOT on your server or laptop or desktop.
Therefore, the links to images and other files are pointing to the server you are visiting. I created a script
that takes the current URL that you enter and locates the base-URL. So SaranacLake.com/images/png1.png shows just SaranacLake.com. Then, for images and other files that the page links to local files like an image, it would be like Once you copy this to your
own storage, that link is broken. I have a very short script that places the base-URL at the front of these.
Then, when you view the local page version on your system, it pulls the image from the live site. The images
should not change on their server, so it is viewable. I also added in an option that would let me save the
actually image instead of reloading it from their server. But, that script got very tricky as I needed to change the location pointers to a new local location. So, to fix all of this, it would be a bit of code. More than we
would want here.
So, do you have a live server somewhere? Do you have a server set up on your computer using Wamp or Xamp or something similar? I am asking because you would need a place to save the saved files.
Hi there! Thanks for the reply. It seems that your latest response deals more with my questions above on how I still cannot properly capture more cmplex web pages from the NYT and Washington Post.
I would be interested in talking more about that, but my latest post was asking why when I went to latesthackingnews.com that instead of that web page being saved, your scraping program is what got saved?!
To be clear, I loaded your scrap_page.php script in NetBeans locally, and then I pasted sin the above URL and a web page title, and when I click download the html file that gets saved to my hard drive is not the web page I was trying to save, but instead your scrping script as in the web form with URL and Article Title.
That s the craziest thing I have ever seen. It is like for that one page the script recursively savs itself?!
Any ideas why this happened just for that one web page?
Well, that one page is complicated to explain. I did a quick review of the code on that page. It contains a ton odd coding and it uses the Javascripting and AJAX calls to load items.
This means that you would need to probably use Curl to grab the entire page after the items are loaded.
Sometimes scraping can be tricky. But, it also boils down to the problem with the external links not being saved.
You should have a personal message to read. A colored number on your icon in the upper right of the page. Please read it.
Not sure why that code would show itself since PHP is not possible to show on a server. My guess is that it is a caching issue of some sort. PHP is never seen in ANY scraped or loaded code or webpages. Just can not happen. The server processes the PHP and then sends it to the browser where CSS and Javascript and HTML run. You would NEVER be able to see PHP code from a website page. UNLESS you coded a page incorrectly and dropped a <?PHP line or used a <CODE tag. So, my guess on that is you did something wrong when you copy n’ pasted the code.
When I go to save this particular “LatesthackingNews .com” webpage, your script creates a file called “LatestHackingNews.com.html” but when I open that .html file I end up seeing this…
Considering that your script simply uses the function file_get_contents($url) to load the web page and then we strip out all of the < script ></ script > content, I fail to see why the saved file ends up being the web page I see displayed when I run your (renamed) download_article.php script?!
Follow me now?
Not a major deal, just annying and strange…
For the last 100 web pages I have tried to save using your script, it works great - again other than some of the fanier NYT pages don’t get entirely captured the way that I want because they are dynamic webpages that use JavaScript to assemble the web pages themselves.
Well, I looked back to how the script saved pages and it might be due to using the browser object.
If that is the problem, you can replace this part:
// I do not understand what the following lines are doing?!
header('Content-Disposition: attachment; filename="scraped_file.html"');
header('Content-Type: text/html');
header('Content-Length: ' . strlen($webpage));
header('Connection: close');
echo $webpage;
This does not actually set the file types, but, that should not be important as the extension will take care of it.
I could not view your posted image, might be cuz my systems are all busy here today! Did you get my personal message? I will send it again…
I did some further research and found that Curl functions capture webpages a little better in some cases.
Here is the Curl funciton I am currently using in another scraper system:
// CURL function to grab pages, returns error messages if issues...
function UrlGetContentsCurl(){
// Parse the argument passed and set default values
$arg_names = array('url', 'timeout', 'getContent', 'offset', 'maxLen');
$arg_passed = func_get_args();
$arg_nb = count($arg_passed);
if (!$arg_nb){
echo 'At least one argument is needed for this function';
return false;
}
$arg = array (
'url' => null,
'timeout' => ini_get('max_execution_time'),
'getContent'=> true,
'offset' => 0,
'maxLen' => null
);
foreach ($arg_passed as $k=>$v){
$arg[$arg_names[$k]] = $v;
}
// CURL connection and result
$ch = curl_init($arg['url']);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)");
curl_setopt($ch, CURLOPT_RESUME_FROM, $arg['offset']);
curl_setopt($ch, CURLOPT_TIMEOUT, $arg['timeout']);
$result = curl_exec($ch);
$elapsed = curl_getinfo ($ch, CURLINFO_TOTAL_TIME);
$CurlErr = curl_error($ch);
curl_close($ch);
if ($CurlErr) {
echo $CurlErr;
return false;
}elseif ($arg['getContent']){
return $arg['maxLen']
? substr($result, 0, $arg['maxLen'])
: $result;
}
return $elapsed;
}
But, you need a full file for this. I could not post that here as this site does not let us even if we are ADMIN’s or not. Therefore, I posted it to your private messages. Download it and unzip it and it might work better than our previous versions. Hope it helps.




{kind=link}