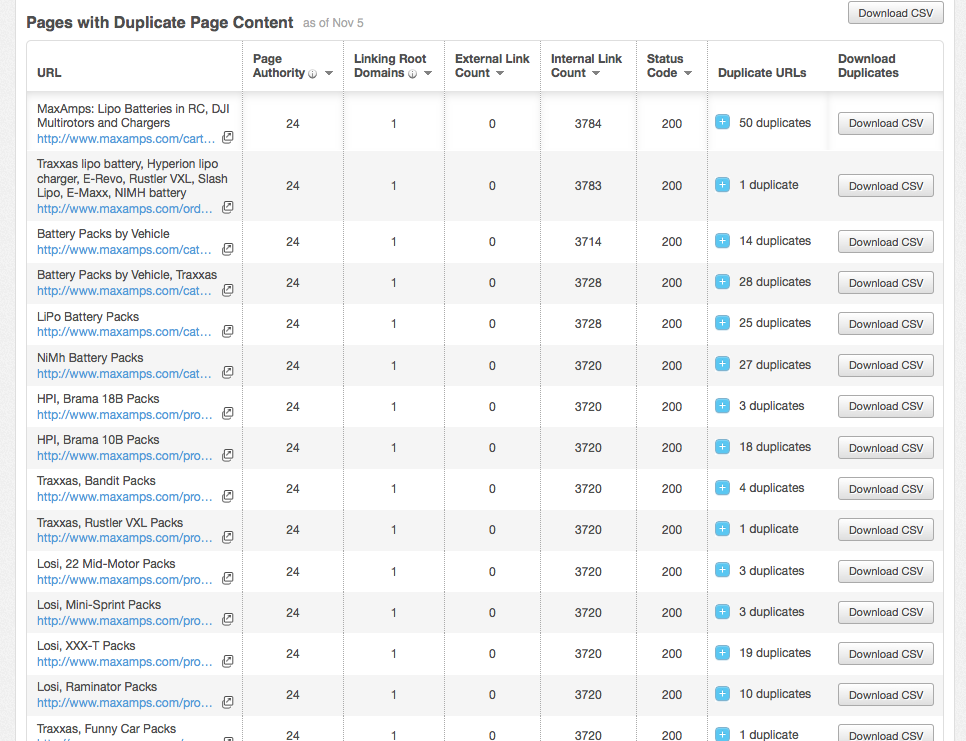
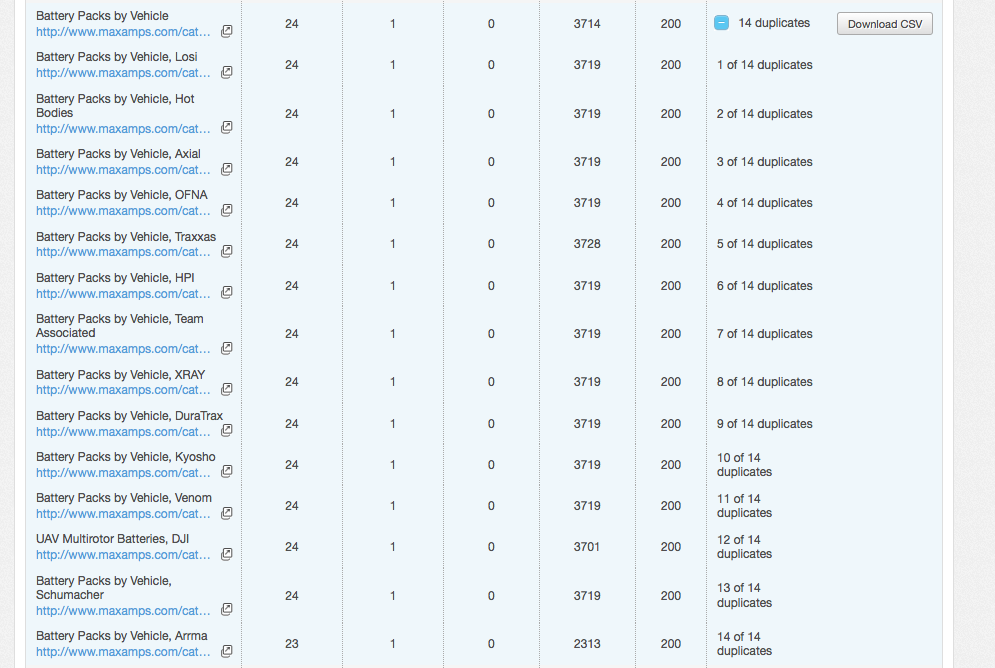
I can understand moving from online retail. However, our products are popular enough and unique enough to make plenty of profit. Which is really why I want to get this fixed in hopes that it will bring even more traffic and profit. And just so it can run as efficiently as possible, of course.
Okay, the coding for our Category pages is below. Just because I think it will help. This is the one and ONLY Category.php page we have that loads every single category page our site has. What exactly would I need to place in the header of this page to help? I am asking this, of course, hoping you might know or be able to give me an idea of the information I need to solve this. All the information you have provided is very helpful but when it comes down to applying it to my site I still don’t see how it would work.
<?php
session_cache_limiter('none');
session_start();
ini_set('url_rewriter.tags', '');
include "vsadmin/db_conn_open.php";
include "vsadmin/inc/languagefile.php";
include "vsadmin/includes.php";
include "vsadmin/inc/metainfo.php";?>
<?php
if($topsection != "") print $topsection . ", ";
print $sectionname?>
">
td{font-family:Tahoma;font-size:11px;color:#000000}
a{color:#800000}
.date{font-family:Tahoma;font-size:10px;color:#787878;font-weight:bold;padding-left:10px;padding-top:10px;}
.cap{font-family:Tahoma;font-size:10px;color:#FFAA00;font-weight:bold;padding-left:10px;padding-top:2px;}
div.Section1
{page:Section1;}
.style2 {color: #FF0000}
|
<td width="171" rowspan="2" valign="top">
<table height="53%" border="0" cellpadding="0" cellspacing="0" bgcolor="#FFFFFF">
<tr>
<td valign="top"> <div id="search">
<form method="POST" action="search.php">
<input type="hidden" name="posted" value="1">
<input type="hidden" name="sprice" value="">
<input name="stext" type="text" class="search-field" id="SearchText" size="20" value="Search.." onFocus="if(this.value == 'Search..') {this.value = '';}" onBlur="if (this.value == '') {this.value = 'Search..';}"/>
<input type="submit" value="" class="search-go" />
</form>
</div>
</td>
</tr>
<tr>
<td width="171" background="images/bg1.jpg" valign="top">
<div style="padding-left:0px;padding-top:0px;">
<table width="160" cellpadding="0" cellspacing="0" border="0">
<tr>
<td valign="top" style="padding-left:0px;">
<?php include "vsadmin/inc/incfunctions.php"; ?>
<?php $menustyle='verticalmenu3'; ?>
<?php include "vsadmin/inc/incmenu.php"?>
<?php include "includes/leftnavigation_dynamic.htm"; ?>
<tr>
<td width="171" height="15" background="images/bgform3.jpg" valign="top"> </td>
</tr>
<tr>
<td valign="top"><img src="images/capform2.jpg"></td>
</tr>
<tr>
<td width="171" height="56" valign="top" background="images/bg2.JPG">
<div style="padding-left:10px;">
<table cellpadding="0" cellspacing="0" border="0">
<tr>
<td width="150" valign="top" align="center"> <SCRIPT LANGUAGE="php">
include “vsadmin/inc/incminicart.php”;
<tr>
<td width="171" height="15" valign="top" background="images/bgform3.jpg"> </td>
</tr>
<tr>
<td valign="top"><img src="images/capnews.jpg"></td>
</tr>
<tr>
<td width="171" height="50%" style="background-repeat:no-repeat;background-position:bottom left" valign="top">
<table cellpadding="0" cellspacing="0" border="0">
<tr>
<td width="150" valign="top" align="center"><SCRIPT LANGUAGE="php">
include “includes/login.htm”;
include “includes/billmelater.htm”;
<tr>
<td width="171" height="15%" style="background-repeat:no-repeat;background-position:bottom left" valign="top">
</td>
</tr>
<tr>
<td width="171" height="15%" style="background-repeat:no-repeat;background-position:bottom left" valign="top"> </td>
</tr>
</table> </td>
<td width="729" height="19" valign="top"><img src="images/midtop_728.jpg" width="728" height="19"></td>
<td valign="top"><!-- InstanceBeginEditable name="Body" -->
<table width="100%" height="100%" border="0" cellpadding="0" cellspacing="0">
<tr>
<td width="569" background="images/bgmid_728.gif" height="210" valign="top"><div align="left">
<SCRIPT LANGUAGE="php">
include “vsadmin/inc/inccategories.php”;
|
<td colspan="2" background="images/tile3.jpg"><table width="900" height="100%" border="0" align="center" cellpadding="0" cellspacing="0">
<tr>
<td colspan="2"><table cellpadding="0" cellspacing="0" border="0">
<tr>
<td><img src="images/p01.jpg"></td>
<td rowspan="3" width="263" height="123" background="images/great22.jpg"></td>
</tr>
<tr>
<td><a href=""><img src="images/f01.jpg" border="0"></a><a href=""><img src="images/f02.jpg" border="0"></a><a href=""><img src="images/f03.jpg" border="0"></a><a href=""><img src="images/f04.jpg" border="0"></a><img src="images/p02.jpg" border="0"></td>
</tr>
<tr>
<td width="437" height="66" align="left" background="images/footer.jpg" style="padding-left:25px;padding-top:5px;"><p style="margin-top: 0; margin-bottom: 2px"> <font color="#FFFFFF">1015 W Garland Ave, Spokane</font><font color="#FFFFFF">, WA 99205
888.654.4450</font></p>
<p style="margin-top: 0; margin-bottom: 2px"> <font size="1" color="#FFFFFF">Traxxas®, Rustler®, and Stampede® are
registered trademarks of Traxxas®, used with permissions </font>
<p style="margin-top: 0; margin-bottom: 2px"> <font color="#FFFFFF" size="1"> Site Designed by: <a target="_blank" href="http://www.maxxfusion.com"> <font color="#FFFFFF">MaxxFusion Technologies</font></a></font></td>
</tr>
</table></td>
<td width="100%" align="left" background="images/tile3.jpg"><img src="images/great222.jpg" width="421" height="123" border="0"></td>
</tr>
</table></td>